The mystery of the decryption errors: A two‑line bug fix
In distributed systems the most unsettling failures are the ones that almost don’t fail. Everything “works,” but a tiny percentage of requests behave strangely. The impact might be low, but the implications can be serious, especially when encryption is involved.
This is the story of a small, gradually increasing rate of decryption errors in a production system, what it took to track them down, and the deceptively simple fix.🕵️
Copilot and AI agents have become a big part of my development and investigation workflow, but due to the nature of this bug it wasn’t very helpful during investigation. However, Copilot did inadvertently lead me to the root cause in the end!
The symptom
The system in question is a fairly typical backend service written in Go, with data stored in MySQL. Some of the data stored is sensitive and so encrypted at rest. It’s not really important what this data is, but if the data can’t be decrypted correctly there’s a fallback path that allows the system to continue functioning.
That fallback mattered, because we saw a small but steady trickle of decryption errors over time. The rate was growing in proportion to the volume of data being decrypted, and at a rate of less than 1% of all requests.
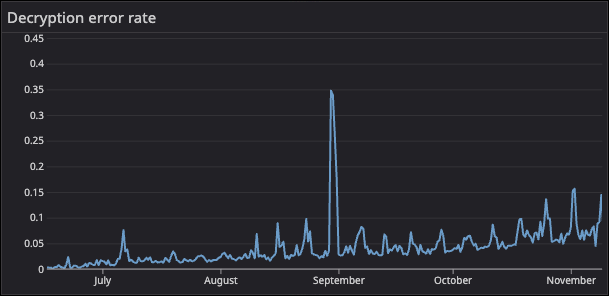
During these events, the encryption library was returning a clear error message:
Ciphertext could not be decrypted.
Even at a very low rate, that kind of error is concerning! It points to either:
- the secret key used for decryption is sometimes wrong, or
- the stored encrypted bytes are sometimes corrupted (or are corrupted after retrieval).
The first clue
One of the earliest observations was that when the error occurred, within a single request multiple encrypted fields would always fail decryption together. That was important because it suggested the problem wasn’t transitive, in the sense that the decryption could be retried and succeed. When decryption failed for one field, it consistently failed for all fields within that request.
This strongly suggested the problem was either:
- something about how values are retrieved for that request, or
- memory reuse / mutation within the process.
Narrowing down the bug
The investigation went through the kinds of steps you’d expect when debugging something that could be data corruption.
1) Validate the shape of the retrieved ciphertext
By instrumenting the length of the encrypted bytes coming back from the database, I could check whether truncation or unexpected formatting was involved. The ciphertext lengths were consistently as expected.
So not obviously truncated.
2) Add targeted tests around “encryption enabled/disabled” behaviour
There were cases where encrypted fields might be absent, and the system should interpret that as “encryption disabled for this record.” Tests confirmed that behaviour was correct and stable.
So not a logic bug around “missing encrypted fields.”
3) Correlate with larger result sets
A pattern emerged where most failures happened when fetching multiple records in a single query, generally greater than five rows.
So only manifests when scanning multiple rows.
4) Verify stored data by batch processing
I created a batch job (internally we call them “transitions”) that iterated through all stored rows in the database and attempted decryption. Everything decrypted successfully.
Very reassuring! The encrypted data in storage seemed fine.
5) Confirm the decryption secret wasn’t changing
Instrumentation and small refactors verified that the decryption secret being used in-process was stable and correct.
So not a case of “wrong key.”
The breakthrough
The batch job I created to verify the encrypted data had been scanning the encrypted bytes directly into a []byte.
I had used Copilot coding agent to help write the transition quickly, so at the time I didn’t think much of it, but in the main application code the encrypted bytes were being scanned into a different type.
That type was a custom type called Bytes that implemented the database/sql scanner interface.
When the batch job was modified to use the same Bytes scanner type, I was suddenly able to reproduce the decryption errors!💡
The bug
Many SQL drivers return []byte for binary columns, and they may reuse the backing array for performance as they iterate through rows.
If your Scan method simply assigns that slice then you might be keeping a reference to a buffer that the driver will overwrite when scanning the next row.
b.Bytes = bytes
This is what was happening:
- The SQL driver provides a
[]byteslice when scanning - The
Scanmethod directly assigns this slice tob.Bytes - The SQL driver may reuse the underlying memory for this slice across multiple rows
- By the time we try to decrypt the data in one of the rows, the data has been overwritten with data from subsequent rows
The ciphertext length was correct, but the bytes were just wrong! That’s what was producing our intermittent, confusing decryption failures.
The fix
The fix was exactly what you’d expect once you know the behaviour—make a defensive copy in Scan.
func (b *Bytes) Scan(value interface{}) error {
if value == nil {
b.Bytes, b.Valid = nil, false
return nil
}
bytes, ok := value.([]byte)
if !ok {
return errors.New("failed to assert column value as type []byte")
}
b.Valid = true
// Defensive copy to avoid referencing driver-owned memory
b.Bytes = make([]byte, len(bytes))
copy(b.Bytes, bytes)
return nil
}
So this is a cautionary tale, that when implementing Scan you need to be aware that the []byte you receive may be reused by the driver! ⚠️